
micro:bitの5×5のLEDディスプレイがマス目に見えてきて、そういえばN-queen問題もマス目にクイーンを置く問題だよな、と思い至りました。そこでmicro:bitで5-queen問題を解いてみようと思います。せっかくなのでmicro:bitでどれだけの計算性能を出せるのか見てみることにし、ついでにPythonとC++で同じプログラムを作ってどれだけ差がでるのかを見てみます。計算性能の測定が目的なので、バックトラック法のようなロジカルな解法ではなく、ニューラルネットを使った数値計算型の解法を使って試してみることにします。
5-queen問題とニューラルネットについて
一般的にはN-queen問題と呼ばれているもので、N×Nのマス目がある盤面上に、チェスの駒であるクイーンをお互いに取られないようにN個配置する配置方法を求める問題です。通常はチェス盤に合わせてN=8としますが、micro:bitは5×5のマス目なので今回はN=5の場合で考えます。ちなみにクイーンは上下・左右・斜めのいずれの方向にも任意の数だけ移動できる駒で、将棋でいえば角と飛車を合体した動きに相当します。たとえばN=4の場合の解は回転と反転を除くと基本的に1個しかなく、以下のパターンのみとなります。
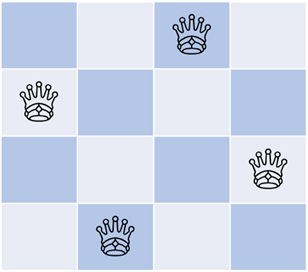
これの解法にはいくつかのやり方があるのですが、今回はニューラルネットを使って解いてみます。エネルギー関数の設定には調べる限り2種類あるのですが、今回はこの研究レポートで述べられている方式を採用させていただきました。
Python版
まずPythonで作ってみます。Pythonはmicro:bit公式が用意しているオンラインエディタが使えます。NumPyは使えなさそう、かつPyhonで2次元配列を使うと遅そうなので、1次元配列を使って展開することにします。実装上で特段の工夫はしていません。なおPythonで5×5のLEDに任意の画像を表示する場合は、"aaaaa:bbbbb:ccccc:ddddd:eeeee"という文字列を引数としてImageクラスのオブジェクトを作り、これをdisplay.show関数に渡してあげれば良いです。a~eの部分には0~9の1桁の数値が5個まで入り、0が消灯、1~9が点灯で、数字が大きいほど明るく点灯します。各行はコロンで区切り、1行目から5行目まで順に並べてください。
import random
from microbit import *
n = 5
du = [0.0] * (n * n)
u = [0.0] * (n * n)
v = [0] * (n * n)
A = 1.0
B = 1.0
C = 1.0
def initialize(u, v, n):
for i in range(n * n):
u[i] = random.uniform(-1.0, 1.0)
if u[i] > 0.0:
v[i] = 1
def judge(v, du, n):
number_of_queens = 0;
for i in range(n * n):
if v[i] == 1:
if du[i] == 0.0:
number_of_queens += 1
return number_of_queens == n
def print_network(v, n):
result = ""
for i in range(n):
for j in range(n):
result = result + str(v[i * n + j] * 9)
result = result + ":"
image = Image(result)
display.show(image)
display.show("Q")
while True:
if button_a.is_pressed():
break
while True:
trial = 1;
found = False;
while True:
initialize(u, v, n)
for epoch in range(1, 100):
for i in range(n):
for j in range(n):
s = 0.0
du[i * n + j] = 0.0
for k in range(n):
s += v[i * n + k]
du[i * n + j] += -A * (s - 1)
s = 0.0
for k in range(n):
s += v[k * n + j]
du[i * n + j] += -A * (s - 1)
s = 0.0
for k in range(-n + 1, n):
if k != 0 and i - k >= 0 and i - k <= n - 1 and j - k >= 0 and j - k <= n - 1:
s += v[(i - k) * n + j - k]
du[i * n + j] += -B * s
s = 0.0
for k in range(-n + 1, n):
if k != 0 and i - k >= 0 and i - k <= n - 1 and j + k >= 0 and j + k <= n - 1:
s += v[(i - k) * n + j + k]
du[i * n + j] += -B * s
c = False
for k in range(n):
if v[i * n + k] == 1:
c = True
break
if c == False:
du[i * n + j] += C
c = False
for k in range(n):
if v[k * n + j] == 1:
c = True
break
if c == False:
du[i * n + j] += C
for i in range(n):
for j in range(n):
u[i * n + j] += du[i * n + j]
v[i * n + j] = 1 if u[i * n + j] > 0 else 0
print_network(v, n)
if judge(v, du, n):
found = True
break;
if found == True:
break
trial += 1
total = (trial - 1) * 100 + epoch
while True:
if button_a.is_pressed():
break
elif button_b.is_pressed():
display.scroll(str(total))
print_network(v, n)
C++版
次にC++版です。比較のためにPython版とほぼ同じプログラムとしています。C++の開発環境はmicro:bit公式では用意していませんが、micro:bitの中身はmbedですので、ARMのmbed開発環境が使えます。実際に作る場合は、プロジェクトにmicrobitモジュールを追加した上で、ヘッダファイルMicroBit.hをインクルードしてください。
で、このC++版の開発にはかなり苦労させられました。アルゴリズム自体は問題ないのですが、micro:bitに書き込むとなぜか失敗したり、正常に書き込めているように見えても何も動いていなかったり……。まだ確定できていませんが、おそらくコンパイルしてできたオブジェクトのサイズが大きすぎてmicro:bitに入りきっていないのではないかと思っています。1行削ると動いたり、1行増やすと突然動かなくなったりするので。なのでなるべくオブジェクトが大きくなり過ぎないようにいくつかの工夫をしています。
- 不要なライブラリは使わない。
- C++11で追加された新しい乱数ライブラリ<random>は使わずレガシーなrand()関数を使用する。
- 疑似乱数のseedの設定にtime()関数は使わない。その代わりAボタンを押すまでrand()関数を実行するものとして、ユーザからの待ち時間をseed相当とする。
- doubleではなくfloatを使う。
- 浮動小数型のN×Nの配列を2個作る必要があるので、1要素のビット幅をなるべく小さくしてメモリ使用量を削減する。
- error()関数をオーバーライドして空にする。
- mbedのバイナリサイズを減らす方法を参考。error()関数の中で呼び出されるprintf()関連の関数でランタイムライブラリがリンクされてしまうのを防ぐ。
この他にも以下のようなメモリをケチる手段がありそうです。いずれ検討してみたいと思います。
- 浮動小数ではなく固定小数または整数のみを使う。
micro:bitのMCUであるARM Cortex-M0には浮動小数ユニットは実装されていない。つまりmicro:bitで浮動小数を使うと、浮動小数エミュレーション用のランタイムライブラリがリンクされているはず。しかもこのエミュレーションコードがインライン展開されたりすると、それだけでものすごいコード量になると予想される。 - MicroBitランタイムを使わずに直接ハード(LED)を制御する。
MicroBitランタイムをリンクするとそれだけで400KB強ほどhexファイルのサイズが大きくなることが実験により分かっている。その代わりにmbedライブラリに変更することで280KB強の増加で済む。ただしLEDマトリックスの制御には別スレッドを立ち上げて1ラインごとのダイナミック制御する必要があり、プログラミングの敷居が高くなる。
#include "MicroBit.h"
using namespace std;
MicroBit uBit;
MicroBitButton buttonA(MICROBIT_PIN_BUTTON_A, MICROBIT_ID_BUTTON_A);
MicroBitButton buttonB(MICROBIT_PIN_BUTTON_B, MICROBIT_ID_BUTTON_B);
static int n = 5;
static float A = 1.0;
static float B = 1.0;
static float C = 1.0;
static int trial = 0;
static int epoch = 0;
static MicroBitImage img(5, 5);
void error(const char* format, ...) {}
float drand() {
return ((float)rand() / RAND_MAX) * 2.0 - 1.0;
}
void initialize(float *u, int *v, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
u[i * n + j] = drand();
v[i * n + j] = (u[i * n + j] > 0.0) ? 1 : 0;
}
}
}
bool judge(int *v, float *du, int n) {
int number_of_queens = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (v[i * n + j] == 1 && du[i * n + j] == 0.0) {
number_of_queens++;
}
}
}
return number_of_queens == n;
}
void print_network(int *v, int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
img.setPixelValue(i, j, v[i * n + j] * 255);
}
}
uBit.display.print(img);
}
int main() {
uBit.init();
uBit.display.print("Q");
while (!buttonA.isPressed()) {
drand();
}
float du[n * n];
float u[n * n];
int v[n * n];
while (true) {
trial = 1;
epoch = 1;
bool found = false;
while (true) {
int i, j, k;
float s;
bool c;
initialize(u, v, n);
for (epoch = 1; epoch <= 100; epoch++) {
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
s = 0.0;
du[i * n + j] = 0.0;
for (k = 0; k < n; k++) {
s += v[i * n + k];
}
du[i * n + j] += -A * (s - 1);
s = 0.0;
for (k = 0; k < n; k++) {
s += v[k * n + j];
}
du[i * n + j] += -A * (s - 1);
s = 0.0;
for (k = -n + 1; k < n; k++) {
if (k != 0 && i - k >= 0 && i - k <= n - 1 && j - k >= 0 && j - k <= n - 1) {
s += v[(i - k) * n + j - k];
}
}
du[i * n + j] += -B * s;
s = 0.0;
for (k = -n + 1; k < n; k++) {
if (k != 0 && i - k >= 0 && i - k <= n - 1 && j + k >= 0 && j + k <= n - 1) {
s += v[(i - k) * n + j + k];
}
}
du[i * n + j] += -B * s;
c = false;
for (int k = 0; k < n; k++) {
if (v[i * n + k] == 1) {
c = true;
break;
}
}
if (c == false) {
du[i * n + j] += C;
}
c = false;
for (int k = 0; k < n; k++) {
if (v[k * n + j] == 1) {
c = true;
break;
}
}
if (c == false) {
du[i * n + j] += C;
}
}
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
u[i * n + j] += du[i * n + j];
v[i * n + j] = (u[i * n + j] > 0) ? 1 : 0;
}
}
print_network(v, n);
if (judge(v, du, n)) {
found = true;
break;
}
}
if (found) {
break;
}
trial++;
}
int total = (trial - 1) * 100 + epoch;
while (true) {
if (buttonA.isPressed()) {
break;
}
else if (buttonB.isPressed()) {
uBit.display.scroll(total);
print_network(v, n);
}
drand();
}
}
return 0;
}
結果
それぞれの実行結果を示します。
Python版
C++版
やはりC++版の方がPython版よりも圧倒的に速いです。Pythonはインタプリタ実行しているので、コンパイルしてネイティブ実行しているC++には太刀打ちできないですね。
PythonでもNumPyが使えれば高速になる可能性はありますが、まだmbed用のNumPyは存在しないみたいです。あったとしてもmicro:bitに入るサイズに収まるのか不明ですが……。
まとめ
micro:bitでもC++を使えば高速処理が可能になります。しかし規模の大きなプログラム、特に多種のライブラリを使うようなプログラムはmicro:bitに入りきらないおそれがあるので、ライブラリの濫用は控えめにする必要があるでしょう。できれば整数演算だけで済むような処理が向いていると思います。


コメント